Keras: 用 Unet 學習資料讀取及抽換資料的思路
以前自已摸索深度學習時,都是使用現成的資料集去實作相關程式碼,例如 MNIST 數字集、Cifar10 …等,網路上也充斥各種範例程式,雖然可以很快去完成一支訓練程式,很輕鬆的建構出神經網路架構 (ctrl+c ctrl+v),殊不知,讀資料才是最重要的XD
也因為對於資料讀取這件事不夠了解,所以要換成自己的資料就卡關了,也不知道如何製作輸入影像及標記資料,間接導致換資料變得很困難,至少對於一些本身背景就不是寫程式的人更是如此,也因此我們除了學習相關 API 之外,也應該學習如何建立及讀取資料。
本文使用 tensorflow2 + keras API 實作 Unet 架構,並嘗試用最簡單的方式來學習 tf.data.Dataset 這個資料讀取的方法。
關於深度學習的流程
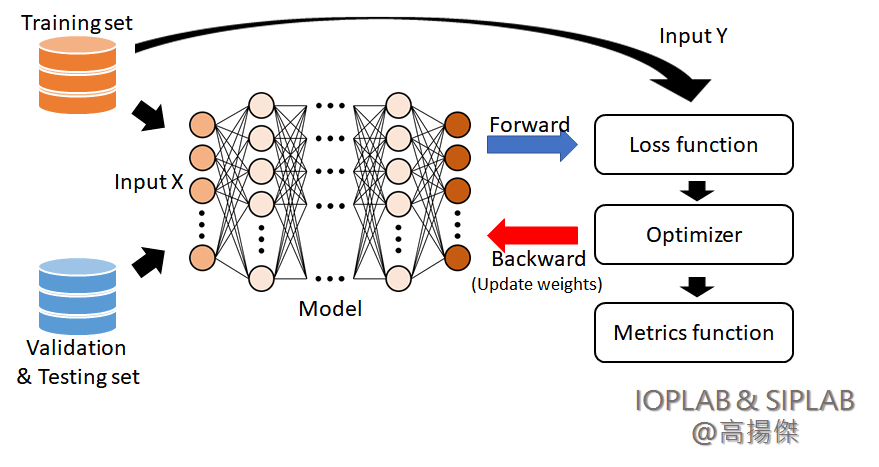
在深度學習中,資料通常可以分成 Input data、Output data 及對應 Ground true data,就是所謂的標記資料,其中 Input data 和 Ground true data 都是要自行準備的,對應上方流程圖就是 Input X 及 Input Y。
補充:整個訓練過程大概是 輸入資料>>神經網路(Forward)>>預測結果>>計算預測與標記誤差(loss function)>>優化神經網路權重(Backward)
思考資料讀取的參數
本文以分割架構作為資料讀取範例,如果想做分類資料的讀取程式,可以參考另一篇文章。
雖說使用 Unet 作為架構,但不一定要建立分割資料,而是先思考這些資料的相關參數,並將這些參數資訊轉成讀取資料的程式碼,確定資料流的方法以後再來決定如何建立資料庫。
例如:
一開始先以 影像大小 去思考
- 輸入是一張 512×512 影像
- 輸出是一張與輸入同樣大小 512×512 的影像
因此可以得知輸入輸出都會是 512×512 的矩陣
接著再去思考 data 裡面的數值
- 輸入影像使用灰階影像並正規化至 0-1
- 輸出一張與原圖相同的灰階影像 (輸出一樣的東西?)
由於前面已經先想好會輸出相同大小的矩陣,所以我們可以先使用任何假資料,先去完成資料讀取,將來根據不同應用抽換標記資料即可
寫好資料讀取方式,再去思考輸出的資料,可能應用如下
去模糊、分割、風格轉換、etc.
可以發現這些應用都是將輸入影像重建出另一種形式的結果,所以只要資料讀取方法建立,其實都是大同小異
實作讀取程式
KERAS 其實也有提供讀取資料的 API 可以使用,但是要修改一些東西時就會很麻煩,因為都封裝起來了,但有了前面概念之後,就會發現任何一支讀資料程式都是差不多概念,所以其實是可以自行建構一套讀資料的程式XD。
自從有了 TensorFlow 2 之後,多了許多 API 可以使用,其中 tf.data 就是讓我們有自行決定資料處理的彈性外,又提供一些共通的功能,讓我們不用自己重新造輪子。
如果今天使用別人專案進行實驗,大部分都會附上抽換資料的方法或步驟,但如果有一些概念以後,要使用別人的程式碼也更容易,也比較知道要怎麼進行修改來增加自己的功能。
不管使用什麼方式,都先建立資料的路徑清單!!!
在講解 tf.data 程式之前,我們先來建立資料清單。大部分資料集下載下來,其實大多都會提供讀取清單,通常是訓練、驗證、測試清單。建立清單一方面是確保資料順序一致性,另一面是對每次結果進行比較,對於訓練結果驗證格外重要。
而本文資料路徑清單是利用 glob 來建立,這個清單都會給 tf.data.Dataset.from_tensor_slices()、tf.data.Dataset.from_generator() 使用。
# 使用 glob 來獲得資料路徑
# 利用正則表示式來辨識圖片路徑
#
# data\in\ -> 輸入影像(image)的資料夾
#
tra_data_in = glob.glob(r"data\in\*.png")
#
# data\out\ -> 標記影像(mask)的資料夾
#
tra_data_out = glob.glob(r"data\out\*.png")
# 建立 dict 來存放路徑
# 給 from_tensor_slices() 使用
tra_data = {}
tra_data["in"] = tra_data_in
tra_data["out"] = tra_data_out接下來,我會介紹兩種方式去讀資料
- tf.data.Dataset.from_tensor_slices()
- tf.data.Dataset.from_generator()
tf.data.Dataset.from_tensor_slices() + map()
- 建立讀取影像的 function
def parse_fn(dataset, **kwargs):
# 分離 dataset dict
path_x = dataset["in"] # for inp image
path_y = dataset["out"] # for out mask
# 讀取 image (使用 tf IO function)
x = tf.io.read_file(path_x)
x = tf.io.decode_image(x, channels=1, expand_animations=False)
y = tf.io.read_file(path_y)
y = tf.io.decode_image(y, channels=1, expand_animations=False)
# 對影像進行正規化,及增加影像通道
x = tf.cast(x, tf.float32) / 255.0
x = tf.expand_dims(x, axis=-1)
y = tf.cast(y, tf.float32) / 255.0
y = tf.expand_dims(y, axis=-1)
return x, x # 回傳資料- 將資料清單
tra_data輸入至from_tensor_slices()並建立 tra_ds 物件
tra_ds = Dataset.from_tensor_slices(tra_data)- 使用
map()function 來嵌入讀取影像的 function
autotune = tf.data.experimental.AUTOTUNE # 自動模式
tra_ds = tra_ds.map(lambda ds: parse_fn(ds), num_parallel_calls=autotune)- 為 tra_ds Dataset 物件設定 shuffle、batch size
tra_ds = tra_ds.shuffle(20).batch(1)特點
- 可以使用
batch()、shuffle()、map()…等方法來設定資料訓練的參數 map()來建立資料讀取 funciton,可以避免總資料量過大而無法放進記憶體- 使用
map()可以加入各種預處理的運算 (用 tf 的 API 來運算) - 使用
tf.py_function()可以整合一些 python 的運算,例如各種資料擴增處理 (但官方建議使用 tf API)
tf.data.Dataset.from_generator()
- 建立 generator function
這邊使用 python 內嵌函數來添加自訂運算
def create_dataset(data_x, data_y, data_shape):
def _generator(data_x, data_y, data_shape): # 直接導入父函數的引數
H, W = data_shape # 取得影像長寬
for n in range(len(data_x)): # 用 for 迴圈去讀取資料
if isinstance(data_x[n], bytes): # 處理字串
x = data_x[n].decode("utf-8")
if isinstance(data_y[n], bytes): # 處理字串
y = data_y[n].decode("utf-8")
# 讀取影像
X = cv2.imread(x, 0)
X = cv2.resize(X, (H,W))
x = X / 255.0
x = tf.expand_dims(x, axis=-1)
X.astype('float32').reshape(H,W,1)
# 讀取影像
Y = cv2.imread(y, 0)
Y = cv2.resize(Y, (H,W))
Y = Y / 255.0
Y.astype('float32').reshape(H,W,1)
yield X, Y
# 回傳 Dataset 物件
return tf.data.Dataset.from_generator(
_generator, args=[data_x, data_y, data_shape],
output_signature=(tf.TensorSpec(shape=data_shape, dtype=tf.float32),
tf.TensorSpec(shape=data_shape, dtype=tf.float32))
)- 建立 Dataset 物件
一般都會是在 generator 中處理批次(batch)資料讀取,但這邊直接用 tf.data API 來處理
tra_ds = create_dataset(tra_data_in, tra_data_out, (512,512)).batch(1)特點
- 與上述方法一樣,可以避免記憶體不足問題
- 能夠更加輕易的導入 python 的運算 (不用使用 tf API,效能會受到 Python GIL 限制)
- 可以將 Keras API 的 preprocessing.image.ImageDataGenerator 包裝成 tf.data.Dataset 連結