深度學習:複習 TensorFlow2 + KERAS 的分類程式
這裡會學到
- 讀取 MNIST 資料
- CNN 模型建立
- 訓練參數設定
- 評估、預測模型
有一些基本的東西這邊就不講了,像是 TensorFlow 環境建立、MNIST 資料集的介紹..等等,直接去看我之前的文章。
程式架構
分成三個檔案:
- MyModel.py
- MyTools.py
- mnist_ds.py
這些檔案可能會隨著我測試的東西而改變,所以檔案說明以 GITHUB 上的 README 為主,檔案用途會寫在上面。
程式流程
- CNN 模型建立
- 讀取 MNIST 資料
- 載入模型、輸出模型架構
- 定義訓練參數
- 訓練模型
- 預測測試資料
- 評估測試資料
程式碼
一、CNN 模型建立 (檔案在 MyModel.py)
建立最簡單的 CNN 來去辨識 MNIST 的數字,包含:
- 一個輸入層
- 兩個卷積層
- 兩個池化層
- 一個扁平層
- 一個全連接層
- 一個 softmax 輸出層
這裡的 CNN 模型架構建立,我是使用 Keras 的 MODEL API 來做。另外我把程式寫成模組來呼叫了,這樣可以跟主要程式分開管理,而且這個檔案也能在其他地方呼叫。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import utils
def LeNet(input_shape):
x_in = layers.Input(shape=input_shape, name="image")
x = layers.Conv2D(filters=16,
kernel_size=(5,5),
activation="relu",
padding='same')(x_in)
x = layers.MaxPooling2D(pool_size=(2,2))(x)
x = layers.Conv2D(filters=32,
kernel_size=(5,5),
activation="relu")(x)
x = layers.MaxPooling2D(pool_size=(2,2))(x)
x = layers.Flatten()(x)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dropout(0.5)(x)
x_out = layers.Dense(10, activation='softmax', name="label")(x)
return models.Model(inputs=[x_in], outputs=[x_out])
二、讀取資料
讀資料的方式,目前我整理出三種方式:
- tensorflow_datasets:直接讀取 TensorFlow 的資料庫,讀格式是屬於第三種的形式。
- tensorflow.keras.datasets.mnist:這是 Keras 的資料庫,讀進來是 NumPy Array。
- tensorflow.data.Dataset:這是 TensorFlow 專門用來讀取 data 的 API,我在這邊是把第二種 NumPy Array,製作成 TensorFlow Dataset 物件。
簡單講就是把 (image data, label data) → Dataset,主要好處應該就是讀資料效能較高,程式寫起來比較直覺一些,也是我這次想記錄一下的原因之一。
其實還有許多讀資料的方法,像是用 tfrecoed、產生器 (Generator) 的形式。前者我一直搞不懂所以沒試過;後者倒是很常用,除了寫過自己的產生器,也會用 Keras 內建的 ImageGenerator() 來做資料擴增,但是這以後有機會再來說吧!
- 先引入資料庫的模組
import tensorflow_datasets as tfds # TensorFlow 的資料庫 (Dataset 物件)
from tensorflow.keras.datasets import mnist # Keras 的資料庫 (NumPy 陣列)
from tensorflow.data import Dataset # 用來製作 Dataset 物件的模組
- 定好要用的參數
batch_size = 100
split = 0.8
- 第一種: tensorflow_datasets (tfds)
tra_ds, val_ds = tfds.load("mnist", split=["train[:80%]", "train[80%:]"])
tes_ds = tfds.load("mnist", split="test")
split_tra = len(tra_ds)
split_val = len(val_ds)
tra_ds = tra_ds.batch(batch_size)
tra_ds = tra_ds.shuffle(split_tra)
val_ds = val_ds.batch(batch_size)
val_ds = val_ds.shuffle(split_val)
tes_ds = tes_ds.batch(batch_size)
- 第二種: keras.datasets.mnist
(tra_im, tra_lb), (tes_im, tes_lb) = mnist.load_data()
# normallization
tra_im_norm = tra_im / 255.0
tes_im_norm = tes_im / 255.0
# one hor encoding
tra_lb_onehot = to_categorical(tra_lb)
tes_lb_onehot = to_categorical(tes_lb)
- 第三種: 把剛剛第二種的 NumPy 陣列轉成 Datasets API
注意:之後的訓練是使用此資料。
split_idx = int(len(tra_im)*split)
tra_ds_im = Dataset.from_tensor_slices(tra_im_norm[:split_idx])
tra_ds_lb = Dataset.from_tensor_slices(tra_lb_onehot[:split_idx])
tra_ds = Dataset.zip((tra_ds_im, tra_ds_lb))
tra_ds = tra_ds.batch(batch_size)
tra_ds = tra_ds.shuffle(split_idx)
val_ds_im = Dataset.from_tensor_slices(tra_im_norm[split_idx:])
val_ds_lb = Dataset.from_tensor_slices(tra_lb_onehot[split_idx:])
val_ds = Dataset.zip((val_ds_im, val_ds_lb))
val_ds = val_ds.batch(batch_size)
val_ds = val_ds.shuffle(len(tra_im)-split_idx)
tes_ds_im = Dataset.from_tensor_slices(tes_im_norm)
tes_ds_lb = Dataset.from_tensor_slices(tes_lb_onehot)
tes_ds = Dataset.zip((tes_ds_im, tes_ds_lb))
tes_ds = tes_ds.batch(batch_size)
其實最主要紀錄的是如何把第二種 np.array 轉成 tf.dataset,因為之後如果用自己的資料才可以自行轉換。如果用了第一種,其實還是沒有學到如何讀取自己的資料。
三、載入模型、輸出模型架構
讀完資料之後,就要載入第一步製作的模型了。由於我另外寫個模組在 MyModel.py 中,因此要先將模型的函數引入進來。這邊我的函數名稱叫做 LeNet(),由於 MNIST 的影像資料大小是 28x28x1 所以數入參數必須設成 (28x28x1) 才行。
from MyModel import LeNet
model = LeNet((28,28,1))
輸出模型架構的部分,我用了兩種方式是去看模型,一種是直接在 console 印出model.summary() ,另一種是用圖形顯示。
- 顯示文字的方式
這邊我把原本 model.summary() 這個方法,自己另外包裝成函數了,功能者要是直接存成文字檔。
""" 存在 MyTools.py """
def save_summary(model, savepath, show=True):
with open(savepath, "w+") as f:
with redirect_stdout(f):
model.summary()
if show:
model.summary()
# 使用前,要先引入 MyTools.py
import MyTools
MyTools.save_summary(model, savepath=logpath+"/model_summary.txt", show=True)
Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
net_in (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 28, 28, 16) 416
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 10, 10, 32) 12832
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 5, 5, 32) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 800) 0
_________________________________________________________________
dense_6 (Dense) (None, 128) 102528
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_7 (Dense) (None, 10) 1290
=================================================================
Total params: 117,066
Trainable params: 117,066
Non-trainable params: 0
_________________________________________________________________
- 使用圖形化來顯示架構
這部分就是使用 Keras 內建的 plot_model() 來畫出架構圖。除了基本畫出模型結構外,還可以設定顯示的矩陣大小以及資料型態。
# 要從 keras 的 utils 中引入
from tensorflow.keras.utils import plot_model
plot_model(model, logpath+"/model_archi.png")
plot_model(model, logpath+"/model_archi.png", show_shapes=True)
plot_model(model, logpath+"/model_archi.png", show_dtype=True)
plot_model(model, logpath+"/model_archi.png", show_shapes=True, show_dtype=True)
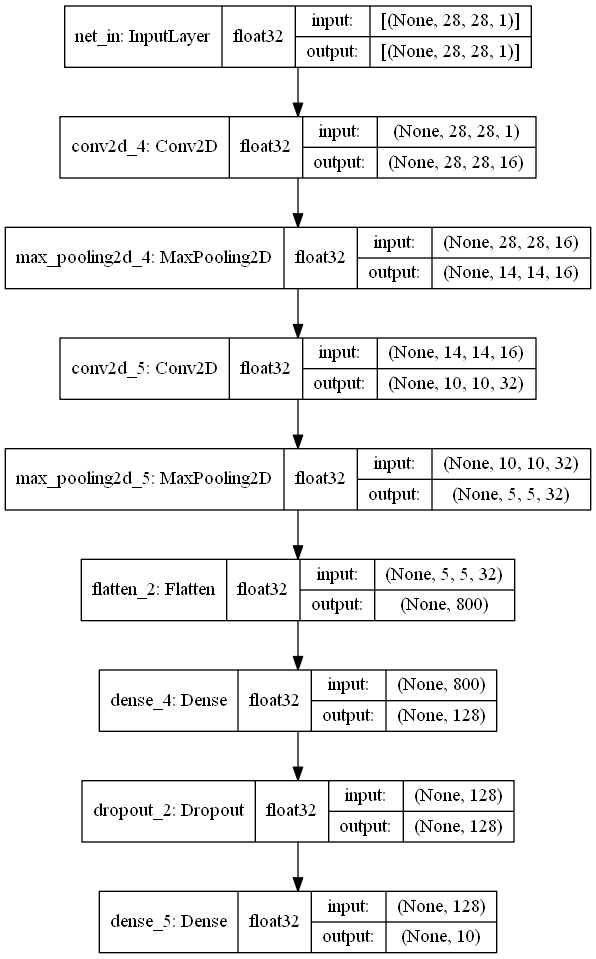
四、定義訓練參數
這邊的訓練參數主要是指優化器 (optimizer)、損失函數 (loss function)、評估函數 (metrics function) 的定義。那優化器我是選擇 Adam(),loss function 我是用 Categorical Cross-entropy 來計算多類別的輸出,然後評估函數是用準確度函數來算。具體定義網路上查就有,有機會再來仔細研讀這些函數。
model.compile(optimizer=Adam(learning_rate=0.0005),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=metrics.CategoricalAccuracy(name="accuracy"))
五、訓練模型
訓練模型的程式主要就是 model.fit() 這個指令。
- 這邊有些需要注意的事情:
- 我讀資料方式是第三種方式 tf.Dataset。
- 訓練之前一定要先
model.compile(),不然是不給訓練。
- 設定 callback
訓練以前我會設定 callback 函數,這邊我列出常用了的幾種:
LearningRateScheduler():這是設定優化器的學習率變化。通常訓練到後面會用較小的學習率來進行訓練。EarlyStopping():提前結束訓練。這是用在訓練還沒到設定的 Epochs 時,訓練的結果已經不會變好,就先停止訓練,避免 overfitting。TensorBoard():這是 Tensorflow 的視覺化工具,其實我很少用。ModelCheckpoint():保存每一次訓練的模型 (模型 or 權重)。這是最常用的 callback 了,基本上保存模型都是用它,中間如果中斷,還可以重新載入模型繼續訓練。CSVLogger():記錄訓練過程。
def scheduler(epoch, lr):
if epoch < 15:
return lr
else:
return lr * tf.math.exp(-0.1)
cbks = [
callbacks.LearningRateScheduler(scheduler, verbose=1),
callbacks.EarlyStopping(patience=3, monitor = "val_accuracy"),
callbacks.TensorBoard(
log_dir=logpath+"/tensorboard", histogram_freq=0, batch_size=32,
write_graph=True, write_grads=False, write_images=False,
embeddings_freq=0, embeddings_layer_names=None,
embeddings_metadata=None, embeddings_data=None,
update_freq="epoch"),
callbacks.ModelCheckpoint(
logpath+"/weights/weights.{epoch:02d}-{val_loss:.5f}-{val_accuracy:.5f}.h5",
save_weights_only=True),
callbacks.CSVLogger(logpath+"/history.csv", separator=",", append=True),
]
- 使用
model.fit()訓練模型
跟前面講的一樣,我讀是第三種方式的資料形式 (tf.Dataset)。
除了設定要訓練集驗證的資料外,還可以初始週期 (initial_epoch) 以及 結束週期 (epochs);通常我會顯示訓練過程,Keras 的好處就是訓練的進度表會直接秀出來;最後就是載入剛剛的 callback list。
history = model.fit(
tra_ds, validation_data=val_ds,
initial_epoch=0, epochs=30, verbose=1,
callbacks=cbks)
- 接續上次的訓練
如果要載入 ModelCheckpoint() 存下的模型繼續訓練,必須先用 model.load_weights() 把權重載入,再來用 fit() 訓練。
model.load_weights(logpath+"/model.h5")
雖然我是不會特別去做檢查,但載入權重之前,可以先用
model.weights來看下權重的數值,接著載入權重 (model.load_weights()) 之後,一樣再使用剛剛的model.weights檢查,看看權重是否有改變,這樣就可以確定權重是否被正確載入。
- 儲存訓練過程 (其實跟剛剛的 callback 是一樣的功能……)
MyTools.save_history(history.history, logpath+"/history_.csv")
- 秀出訓練過程
hist_csv = MyTools.load_history(logpath+"/history.csv")
MyTools.show_history(hist_csv, logpath, 'loss','val_loss')
MyTools.show_history(hist_csv, logpath, 'accuracy','val_accuracy')
- 儲存最後一個模型
這邊其實存模型也有好幾個方式:
- TensorFlow 形式,用
model.save("資料夾路徑")儲存至指定資料夾,相關檔案會自動存出來。 - Keras 的 H5DF 形式 (這也是我以前常用的)
又可以再分成兩種方式:
- 存完整模型,跟剛剛一樣用
model.save("model.h5")儲存,只是這次是直接指定檔案名稱。 - 只存權重,用
save_weights("weights.h5"),也是指定檔案名稱。
- 存完整模型,跟剛剛一樣用
model.save(logpath+"/model") # tensorflow
model.save(logpath+"/model.h5") # H5DF - model
model.save_weights(logpath+"/weights.h5") # H5DF - weights
六、預測測試資料
這邊我會講三個東西:
- 載入已經訓練好的模型
- 評估模型對新資料的能力
- 輸出模型的預測結果
- 載入模型
這邊根據剛剛存資料的方式,也有對應的三種方法。
- TensorFlow 形式 (設定資料夾路徑)
- Keras 形式 (.h5) – 完整模型檔案 (設定檔案路徑)
- Keras 形式 (.h5) – 只有權重檔案 (設定檔案路徑)
model = load_model(logpath+"/model") # tensorflow
# model = load_model(logpath+"/model.h5") # H5DF - model
# model = LeNet((28,28,1)) # 要先呼叫 Model 進來
# model.load_weights(logpath+"/weights.h5") # H5DF - weights
其實程式碼只有兩種,分別是 load_model()、model.load_weights()。需要注意的是載入權重的部分,load_weights() 是屬於 Model 類別的方法之一,因此要載入權重之前,必須要先呼叫 Model 進來。
- 評估測試集
確認模型在測試集上的表現。
eva = model.evaluate(tes_ds, verbose=0)
print("------------------------------")
print("loss:", eva[0])
print("accuracy:", eva[1]*100, "%")
- 預測測試集
將測試資料的預測結果取出來,並將其 onehot 編碼變成數字類別
pre_sco = model.predict(tes_ds, verbose=0) # 取得預測結果
pre_cls = pre_sco.argmax(axis=-1) # 轉成標籤形式 (onehot -> class)
# 秀出第一個預測結果 及 對應的 ground true
print("------------------------------")
print("predict score:", pre_sco[0])
print("predict class:", pre_cls[0])
print("ground true class:", tes_lb[0])
七、評估測試資料
經過一番折騰,終於到最後評估測試資料了。除了訓練時,使用 loss 及 accuracy 來評估模型好壞,也可以用其他評估函數去計算,最常見的應該就是利用混淆矩陣 (Confusion Matrix) 然後去計算準確率 (Accuracy)、精確率(Precision)、召回率(Recall)、F1 Score 等指標。不過這些東西其實不用自己寫了,我是用 scikit-learn 裡的 API 去評估這些指標。
除了使用 scikit-learn 裡的 API 之外,我也自己寫了一些功能進去。相關的程式一樣放在 MyTools.py 模組,利用函數的方式來呼叫了,不這樣的話,主程式好亂啊!!
- 輸出預測結果、混淆矩陣、分類指標
預測結果:這是自己寫得函數,主要就是輸出 檔案編號或是檔案路徑、正確標籤、預測標籤、輸出得分數 (假設 10 類,就有 10 個分數,由於經過 softmax,所以是 0-1 機率分布)
混淆矩陣:這不知道怎麼解釋,就當作視覺化的工具好了,也是計算模型好壞的工具,因為各種評估指標都是根據這個來計算。
分類效能:秀出準確率、精確率、召回率、F1 Score 這些指標。(可看以前文章,不過寫得很爛……)
def export_classification_report(gd, pr, pb, num_cls, logpath,
show_cm=False, show_cmn=False,
show_clrepo=True):
from time import sleep
sleep(1)
# 預測結果
num = len(pb)
log = []
#---------------------#
for i in tqdm(range(num)):
log.append([i, gd[i], pr[i]] + [pb[i][n] for n in range(num_cls)])
log = pd.DataFrame(log, columns=['Name','truth','Predict']+[n for n in range(num_cls)])
log.to_csv(logpath+"/pre_results.csv", encoding='utf-8', index=False)
# 混淆矩陣
cm = pd.crosstab(gd, pr, rownames=['GD'], colnames=['PR'], margins=True)
cm.to_csv(logpath+"/pre_cm.csv", encoding='utf-8')
cmn = pd.crosstab(pr, gd)
cmn = cmn/cmn.sum(axis=0)
cmn.to_csv(logpath+"/pre_cmn.csv", encoding='utf-8')
# 輸出分類報告
cls_report = metrics.classification_report(
gd, pr, target_names=[str(n) for n in range(num_cls)])
with open(logpath+"/cls_report.txt", 'w+') as f:
with redirect_stdout(f):
print(cls_report)
if show_clrepo:
print(cls_report)
# acc_score = metrics.accuracy_score(gd, pr)
cm_report = metrics.confusion_matrix(gd, pr)
if show_cm:
print(cm_report)
if show_cmn:
ppp = cm_report/cm_report.sum(axis=0)
print(np.around(ppp,2))
pb = pre_sco
pr = pre_cls
gd = tes_lb
num_cls = 10
MyTools.export_classification_report(gd, pr, pb, num_cls, logpath)
- 計算錯誤的數量
有時候太久沒看混淆矩陣,會一時之間不知道在幹嘛,通常會用這個程式,直接讓程式告訴我每個類別的錯誤數量。
def err_counter(gd, pr, return_dict=False):
a = pr - gd
err_pr = gd[np.where(a!=0)]
err_gd = pr[np.where(a!=0)]
err_list = {}
for i in range(0,10):
temp_list = {}
total = 0
gd_pos = np.where(err_gd==i)[0]
for j in err_pr[gd_pos]:
if j in temp_list.keys():
temp_list[j] += 1
else:
temp_list[j] = 1
total += 1
print("------------------------------")
print("ground true ID: %d total: %d"%(i, total))
for k in sorted(temp_list.keys()):
v = temp_list[k]
print("%5d - error: %5d"%(k, v))
err_list[i] = temp_list
print("\n total of wrong:", len(err_pr))
if return_dict:
return err_list
pb = pre_sco
pr = pre_cls
gd = tes_lb
MyTools.err_counter(gd, pr)
- 輸出錯誤結果圖
功能就是秀出那些預測錯誤的圖,並用正確標籤及預測類別 (都是數字) 來命名。
def err_imwrite(gd, pr, im, logpath):
_id = err_id(gd, pr)
for i in tqdm(_id):
name = "gd{}_pr{}.png".format(gd[i], pr[i])
tmp = im[i].copy()
tmp = cv2.resize(tmp, (256,256))
cv2.imwrite(os.path.join(logpath+"/pr_err", name), tmp)
pb = pre_sco
pr = pre_cls
gd = tes_lb
MyTools.err_imwrite(gd, pr, tes_im, logpath)
完整程式連結:點我
結語
因為之後工作可能需要使用 TensorFlow 以及 Keras,所以回去複習一下相關的語法及程式,就直接挑 MNIST 數字辨識來當作練習,順便紀錄一下過程。那自從 TensorFlow 2.0 出來之後,推出許多新的 API,似乎也更好的將 Keras 整合進去,但大致上程式碼應該都跟以前一樣 (~~其實那些程式早就不知道去哪了~~),不用重新學習。
這次應該是這裡最長的文章了吧XD
一次寫這麼長的文章實在好累阿,下次應該要分批寫才對。
1,387 則留言
Shao
哈囉您好
有幸於在學習tensorflow時看到您的文章,對於您使用keras的model API有興趣,但您文章中目前的github連結目前失效,想拜讀您的內容學習
不知道您方不方便提供
謝謝您
Best Regards